Data Clustering and Techniques with Weights Over Data Stream
DOI:
https://doi.org/10.54741/asejar.2.4.3Keywords:
data mining, data mining methods, tools & techniquesAbstract
Data mining refers to extract and identify useful information from large sets of data. This term is really a misnomer. Thus, data mining should be named as knowledge mining which rely stress on mining from vast sets of data . An enormous quantity of data is present in the information industry. This data is meaningless until it is converted into useful form of information or help the industries in their business. It is essential to analyze this plenty of data and extract the valuable information from it. In data mining, extraction of information is not only the process to be performed it also involves various other process such as cleaning, integration, data transformation, data mining, pattern evaluation and presentation. When all these processes are completed one will be able to use this valuable information in many applications such as Fraud Detection, Market Analysis, Production Control, Science Exploration, etc.(Dhaka et al.,2018)
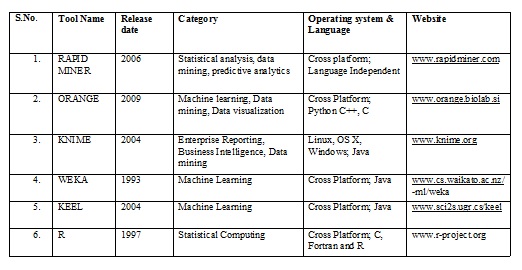
This paper introduces the significance use of data mining techniques such as clustering, association-rules, sequential pattern, statistics analysis, characteristics rules and so on can be used to find out the useful knowledge. Finally, various tools has been explained in this paper.
Downloads
References
R. Dhaka, & A. Kumar (2018). Need and application of data mining. International Journal of Innovations & Advancement in Computer Science, 7(4), 166-169.
Kantardzic, Mehmed. (2003). Data mining: Concepts, models, methods, and algorithms. John Wiley & Sons. ISBN 978-0-471-22852-3.
Mena, Jesús. (2011). Machine learning forensics for law enforcement, security, and intelligence. Boca Raton, FL: CRC Press (Taylor & Francis Group). ISBN 978-1-4398-6069.
Deshpande, Shrinivas & Thakare, V. M. (2010). Data mining system and applications: A review. International Journal of Distributed and Parallel systems. doi: 1.10.5121/ijdps.2010.1103.
Han J, Kamber M, & Pei J (2012). Data mining concepts and techniques. (3rd ed.). Elsevier, Netherlands.
Arora RK, & Gupta MK (2017). e-Governance using data warehousing and data mining. Int J Comput Appl, 169(8), 28–31.
Chen M, Han J, & Yu PS. (1996). Data mining: an overview from a database perspective. IEEE Trans Knowl Data Eng, 8(6), 866–883.
Hung LN, Thu TNT, & Nguyen GC. (2015). An efficient algorithmin mining frequent itemsets with weights over data stream using tree data structure. IJ Intell Syst Appl, 12, 23–31.
Bhatnagar V, Ahuja S, & Kaur S. (2015). Discriminant analysis based cluster ensemble. Int J Data Min Model Manag, 7(2), 83–107.
Liao TW, & Triantaphyllou E. (2007). Recent advances in data mining of enterprise data: algorithms and applications. World Scientific Publishing, Singapore, 111–145.
Algergawy A, Mesiti M, Nayak R, & Saake G. (2011). XML data clustering: an overview. ACM Comput Surv, 43(4), 1–25.
Downloads
Published
How to Cite
Issue
Section
ARK
License
Copyright (c) 2023 Abhishek Verma

This work is licensed under a Creative Commons Attribution 4.0 International License.
Research Articles in 'Applied Science and Engineering Journal for Advanced Research' are Open Access articles published under the Creative Commons CC BY License Creative Commons Attribution 4.0 International License http://creativecommons.org/licenses/by/4.0/. This license allows you to share – copy and redistribute the material in any medium or format. Adapt – remix, transform, and build upon the material for any purpose, even commercially.





