LLM for Financial Services: Risk Analysis and Fraud Detection
Sudhakar VM1*
DOI:10.5281/zenodo.14928807
1* Vinoth Manamala Sudhakar, Sr. Data Scientist (Independent Researcher), Cloud Software Group Inc., Austin, Texas, United States of America.
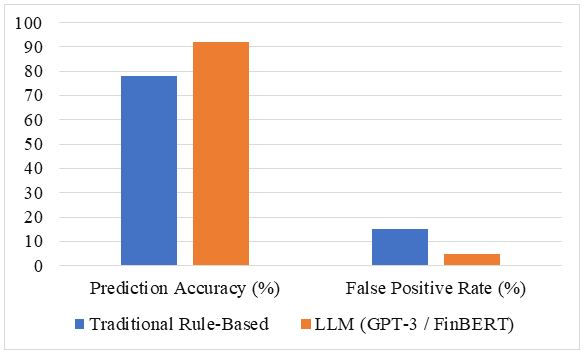
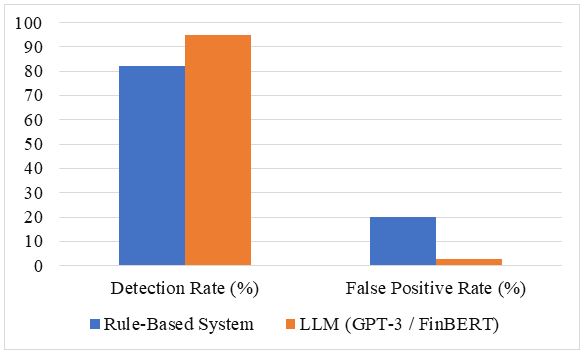
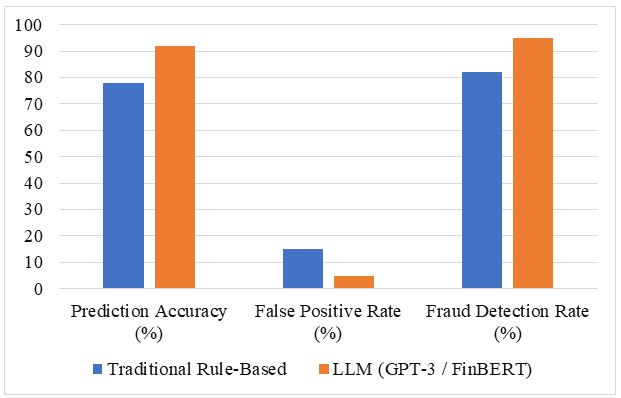
The financial service industry is increasingly suspected by risk management and complicated frauds, because of traditional methods, such as rules based on rules, becomes become Not enough to combat evolutionary threats. This study discovers the potential of large language models (LLM), including GPT-3 and Finbert, to improve risk analysis and fraud detection in the financial sector. LLM, capable of processing structured and non -structured data, provides improvement in detecting models and abnormalities between trading newspapers, customer interaction and talent reports main. A quantitative comparative comparative research design, financial data analysis can access the public and compare LLM performance with traditional systems. Main performance measures - Prediction Accuracy, False Positive Rate, Processing Time, and Fraud Detection Rate- are used to evaluate the effectiveness of the models. The results show the significant potential of LLM to improve financial risk management and detect fraud, provide an effective, accurate and developed approach to modern financial institutions.
Keywords: large language models (llms), gpt-3, finbert, risk analysis, fraud detection, financial services
| Corresponding Author | How to Cite this Article | To Browse |
|---|---|---|
| , Sr. Data Scientist (Independent Researcher), Cloud Software Group Inc., Austin, Texas, United States of America. Email:  |
Sudhakar VM, LLM for Financial Services: Risk Analysis and Fraud Detection. Appl. Sci. Eng. J. Adv. Res.. 2025;4(1):65-70. Available From https://asejar.singhpublication.com/index.php/ojs/article/view/132 |
 |
 ©
©