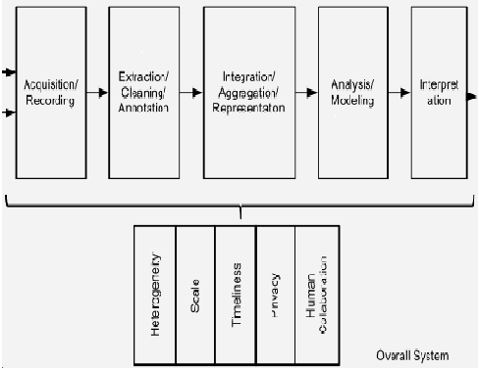
Data Integration, Aggregation, and Representation
There are two ways to create effective database designs: either by developing tools to assist in the design process or by abandoning it entirely and developing techniques that allow databases to be used effectively even if they are not designed intelligently.
Query Processing, Data Modeling, and Analysis
It is fundamentally different from traditional statistical analysis to query and mine Big Data (noisy, dynamic and heterogeneous, inter-related and untrustworthy). Big-data computing environments, declarative querying and mining interfaces, scalable mining algorithms, and integrated, cleaned, trustworthy and easily accessible data are all required for mining Aside from providing intelligent querying, data mining can help improve the data's quality and reliability, as well as uncover its semantics.
As a result of Big Data, interactive data analysis with real-time answers is also possible. An issue with current Big Data analysis is the lack of coordination between database systems, which host the data and provide SQL querying capabilities, and analytics packages that perform various non-SQL processing activities, including data mining and statistical analyses. Both the expressiveness and the performance of the analysis will benefit from a close coupling between declarative query languages and such packages' functions.
Interpretation
A decision-maker, provided with the result of analysis, has to interpret these results. Interpretation involves examining all the assumptions made and retracing the analysis.
Big and Advanced Analytics
The term "big data" has been used to describe data sets that are more than terabytes in size. Automated censors in the office, social media, websites, and robotics are all contributing to the proliferation of structured, unstructured, and semi-structured data in the workplace. With big data analytics, it is possible to put all these fragmented and often disconnected pieces together in order to generate actionable insights for your organisation. Since data is now being generated and captured across multiple channels, KloudData recognises the importance of adjusting business analytics in order to accommodate the various formats in which it is being generated and captured.
Using Sybase IQ and Hadoop, KloudData's big data offering aims to speed up the development and adoption of big data analytics solutions. Big data mining, extraction, analysis, and presentation are all critical components of KloudData's mission to empower business users with the information they need to make better-informed decisions. For today's fast-moving enterprises, our goal is to provide high-availability and scalable analytics solutions.
CHALLENGES IN BIG DATA ANALYSIS
Heterogeneity and Incompleteness
When it comes to information consumption, most people don't mind a lot of variety. Because of its depth and variety, natural language is a useful tool for conveying complex ideas. Computers can only process homogeneous data, so they don't have the ability to discern subtlety. As a result, data must be organised in a precise manner before it can be analysed. e.g. A hospitalised patient who undergoes numerous medical procedures.
It's possible that we'll keep a single record for each procedure or test the patient has, or that we'll keep a single record for their entire hospital stay or for all of their hospital interactions throughout their life. Computer systems are most effective when they can store a large number of identically sized and shaped items in a single location. Incompleteness and errors in data are likely to persist even after cleaning and fixing them. During data analysis, these inconsistencies and errors must be taken into consideration.
Scale
Data volume is increasing at a faster rate than computing resources, but CPU speeds remain the same.
run and execute data processing jobs in order to meet the goals of each workload while also dealing with system failures, which become more frequent as clusters grow in size and cost (that are required to deal with the rapid growth in data volumes).
The traditional I/O subsystem is also undergoing significant transformation, which is a third major change. Increasingly HDDs (persistent data storage and slower random I/O performance) are being replaced by solid state drives and Phase Change Memory.
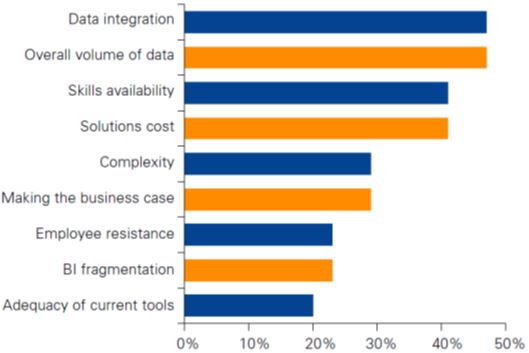
It's necessary to rethink how storage subsystems for data processing systems are designed because the performance spread between sequential and random I/O isn't as wide with these newer storage technologies. According to Fig. 2, big data analytics faces a variety of challenges.


 ©
©