Encrypted Data and Indexing Search Keyword on Multi Cloud
Swetha V1*
DOI:10.54741/asejar.1.2.3
1* V Swetha, Mtech Scholar, Department of Computer Science and Engineering, Veerammal College of Engineering, Dindigul, Tamil Nadu, India.
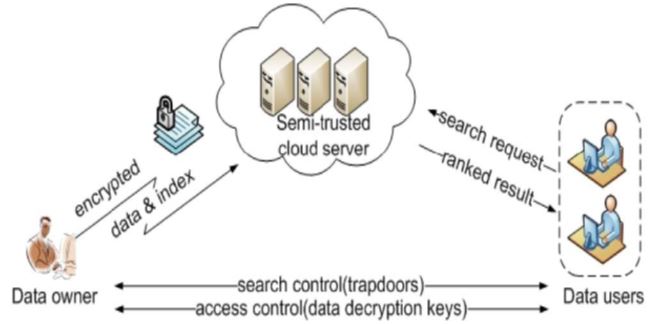
Many data owners are embracing cloud computing to outsource their complex data management systems because of its elasticity and also the cost savings. Prior to outsourcing, all sensitive data must be encrypted to ensure its privacy. The search service must be able to handle multi keyword queries and also provide resemblance ranking in order to meet the statistics repossession needs of cloud users. Privacy-preserving multi-keyword ranking search over encoded cloud data is defined and solved in this paper for the first time, and we establish a set of strict privacy requirements for such a secure cloud data utilisation system when it comes to multi-keyword semantics, "coordinate matching" is the most efficient method. We begin by proposing a basic MRSE scheme based on secure inner product computation, and experiments on the real-world dataset show that the schemes we've proposed do indeed have low computation and communication overhead.. Pseudo (fake) documents that can accurately reflect user information requirements are the focus of a new optimization method we've developed. We also propose a new criterion for evaluating the performance of the restructured web search results, called average precision (CAP). By further extending these two schemes, we can better serve our data search customers. Real-world data experiments show that the proposed schemes do indeed have low computational and communication overhead.
Keywords: multi keyword search, privacy search, cloud computing
| Corresponding Author | How to Cite this Article | To Browse |
|---|---|---|
| , Mtech Scholar, Department of Computer Science and Engineering, Veerammal College of Engineering, Dindigul, Tamil Nadu, India. Email:  |
Swetha V, Encrypted Data and Indexing Search Keyword on Multi Cloud. Appl. Sci. Eng. J. Adv. Res.. 2022;1(2):13-16. Available From https://asejar.singhpublication.com/index.php/ojs/article/view/16 |
 |
 ©
©