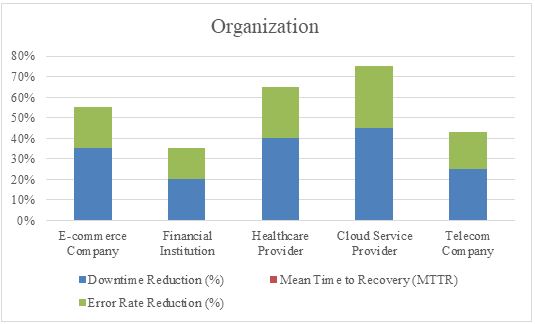
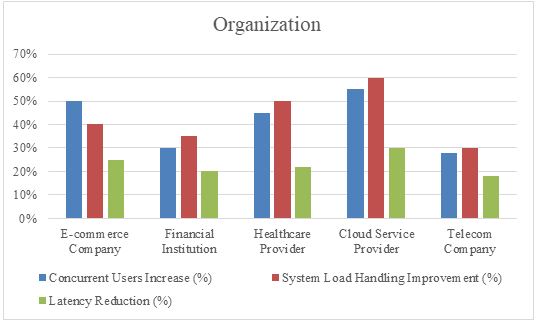
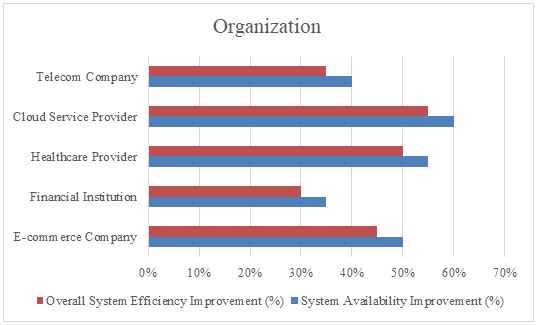
With time, the digitization of sectors, it would most likely play an important role in determining whether these modern systems live or die.
6. Conclusion
This study brings out the enormous benefits that may be gained through the combination of Site Reliability Engineering and Platform Engineering to ensure improved scalability and robustness for systems. Organizations can achieve huge improvements in system availability, performance, and the sheer capacity to take on more users with increased demands through this combination of methodologies. The synergy of SRE and Platform Engineering produces a robust infrastructure in support of digital transformation with even superior operational efficiency and reliability. If an organization seriously considers making their systems more scalable and resilient, then both practices should be considered for optimal utilization. Although there are issues of implementation and specifically required skills, the other benefits are long-term: less downtime, faster recovery, and improved system performance. Future studies may unpack the long-term implications of SRE and Platform Engineering adoption, specifically in terms of customer satisfaction and business outcomes and how future needs in a digital business are met.
References
1. Abili, & S. Hemeda. (2023). Insight-driven digital engineering–A key enabler driving operational intelligence in the energy industry. in SPE Annual Technical Conference and Exhibition, pp. D031S039R006.
2. M. Almufti, & S. R. Zeebaree. (2024). Leveraging distributed systems for fault-tolerant cloud computing: A review of strategies and frameworks. Academic Journal of Nawroz University, 13(2), 9-29.
3. Al-Rubaye, J. Rodriguez, A. Al-Dulaimi, S. Mumtaz, & J. J. Rodrigues. (2019). Enabling digital grid for industrial revolution: self-healing cyber resilient platform. IEEE Network, 33(5), 219-225.
4. Behrendt, E. De Boer, T. Kasah, B. Koerber, N. Mohr, & G. Richter. (2021). Leveraging industrial IoT and advanced technologies for digital transformation. McKinsey & Company, pp. 1-75.
5. R. Chelliah, S. Naithani, & S. Singh. (2018). Practical site reliability engineering: Automate the process of designing, developing, and delivering highly reliable apps and services with SRE, Packt Publishing Ltd.
6. Chinamanagonda. (2023). Focus on resilience engineering in cloud services. Academia Nexus Journal, 2(1).
7. K. Das. (2024). Exploring the symbiotic relationship between digital transformation, infrastructure, service delivery, and governance for smart sustainable cities. Smart Cities, 7(2), 806-835.
8. V. Erhueh, C. Nwakile, O. A. Akano, A. E. Esiri, & E. Hanson. (2024). Digital transformation in energy asset management: Lessons for building the future of energy infrastructure. Global Journal of Research in Science and Technology, 2(2), 010-037.
9. S. George, & T. Baskar. (2024). Driving business transformation through technology innovation: Emerging priorities for IT leaders. Partners Universal Innovative Research Publication, 2(4), 01-14.
10. Huang. (2023). Digital engineering transformation with trustworthy AI towards industry 4.0: Emerging paradigm shifts. Journal of Integrated Design and Process Science, 26(3-4), 267-290.
11. F. Ikwuanusi, O. Onunka, S. J. Owoade, & A. Uzoka. (2024). Digital transformation in public sector services: Enhancing productivity and accountability through scalable software solutions. International Journal of Applied Research in Social Sciences, 6, 2744-2774.
12. Irmak, E. Kabalci, & Y. Kabalci. (2023). Digital transformation of microgrids: a review of design, operation, optimization, and cybersecurity. Energies, 16(12), 4590.
13. Mulder. (2021). Enterprise DevOps for architects: Leverage AIOps and DevSecOps for secure digital transformation. Packt Publishing Ltd.
14. Onesi-Ozigagun, Y. J. Ololade, N. L. Eyo-Udo, & D. O. Ogundipe. (2024). Leading digital transformation in non-digital sectors: A strategic review. International Journal of Management & Entrepreneurship Research, 6(4), 1157-1175.


 ©
©